[DB] ORACLE
[ORACLE] 중복 데이터 조회 쿼리
mewoni
2021. 4. 26. 13:41
반응형
실무에서 사용하는 데이터에서 신규 시스템 구축 후 또는 제대로 설계되지 않거나 전문 DBA가 아닌 고객이 관리하는 엑셀과 같은 형식으로 관리하는 경우에 중복으로 입력된 데이터이 무분별하게 존재하여 사용성을 저해할 수 있다.
이러한 데이터베이스의 무결성을 지키기 위해 중복되는 데이터를 제거하여 UNIQUE하며 NULL값이 될수 없는 새로운 KEY를 설정해야 한다.
* SAMPLE TABLE
TN_RDNMADR ( 도로명주소 ) : 전국 도로명주소를 데이터베이스화 하여 샘플 테이블 구축
* 사용 함수
- 오라클 그룹함수 : GROUP BY , HAVING , PARTITION BY
(1) 중복이 존재하는 컬럼을 GROUP BY로 그룹핑 한 후 HAVING 에서 조건을 COUNT가 1 이상인것으로 SELECT
(2) 분석함수 (PARTITION BY)를 사용하여 SELECT
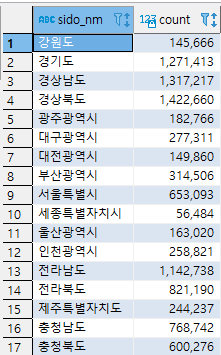
* 사용예시 1
SELECT SIDO_NM, COUNT(*)
FROM TN_RDNMADR R
GROUP BY R.SIDO_NM
HAVING COUNT(*) >1;- SIDO_NM 이라는 컬럼에서 중복되는 값을 조회
- COUNT(*)는 각 시도별로 하위 도로명 주소의 갯수를 의미함.
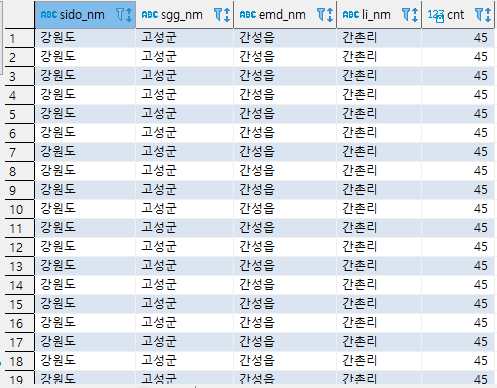
* 사용예시 2
SELECT R.*
FROM (
select SIDO_NM,
SGG_NM,
EMD_NM,
LI_NM,
COUNT(*) OVER(PATITION BY SIDO_NM, SGG_NM, EMD_NM, LI_NM) AS CNT
FROM TN_RDNMADR ) R
WHERE R.CNT > 1;- 시도명과 함께 시군구, 읍면동리 까지 함께 그룹핑 하여 중복된 (시도, 시군구, 읍면동, 리) 그룹을 조회
- PARTITION BY 라는 윈도우 함수 사용
반응형