
1. 데이터베이스 샤딩의 개념
데이터베이스 샤딩(Database Sharding)은 일괄적 관리가 힘든 거대 데이터베이스나 네트워크를 작게 분할하여 저장하여 관리하는 방법입니다. 데이터베이스의 성능과 확장성을 향상 시키는데 중요한 역할을 합니다. 샤딩을 통해 데이터베이스의 부하를 여러 서버로 분산하여 전체 데이터베이스 시스템의 처리량과 성능을 향상시킵니다.
샤드는 샤딩을 통해 분할된 데이터 조각으로, 분산 데이터의 저장 공간을 의미합니다. 샤드 서버에는 각각 일을 분배하는 라우팅 기능을 가진 몽고가 존재합니다. 이와 동일한 메커니즘을 지닌 데이터베이스 샤딩은 주로 대용량 데이터를 처리해야 하는 웹 애플리케이션, 소셜 네트워크 서비스, 온라인 게임 등에서 사용됩니다. 활용되는 분야에 따라 데이터베이스 샤딩, 네트워크 샤딩, 연산 샤딩 등 다양한 종류로 분류할 수 있습니다.
샤딩의 핵심은 샤드 키(Shard Key)를 어떻게 선택하느냐에 있습니다. 샤드 키는 데이터를 분할하고 분산 저장하는 기준이 되며, 샤딩의 성능과 효율성을 결정짓는 중요한 요소입니다. 이러한 분산 관리를 통해 성능 한계를 극복하고 시스템의 확정성과 처리량을 크게 향상시킬 수 있습니다.
2. 데이터베이스 샤딩의 장점
(1) 데이터 처리 속도 및 처리량 향상
가장 큰 장점으로 데이터 처리 속도 및 처리량 향상입니다. 샤딩을 통해 데이터를 여러 서버에 분산 저장 함으로써, 단일 서버에 집중되는 부하를 줄이고 전체 시스템의 처리량과 속도를 증가시킬 수 있습니다.분할된 데이터가 여러 서버에 분산 저장되어 있으므로 병렬 처리가 가능해지며 데이터베이스의 응답 시간이 감소하여 데이터베이스의 읽기와 쓰기 성능이 개선됩니다.
(2) 탈중앙화를 통한 안정성과 보안성 향상
분할된 각 샤드는 독립적으로 운영되며, 한 샤드의 장애가 전체 시스템에 영향을 미치지 않습니다. 바이러스 및 해킹으로 부터 보안성을 확보하고 시스템의 안정성과 가용성을 향상시킬 수 있습니다. 또한 독립적으로 운영됨에 따라 유지 보수와 관리를 용이하게 합니다. 특정 샤드의 백업, 복구, 업그레이드 작업이 다른 샤드에 영향을 미치지 않습니다.
3. 데이터베이스 샤딩의 문제점
(1) 복잡성
샤딩은 데이터 처리 속도를 높여 효율성을 증가시키지만 여러 서버에 데이터가 분산되어 있기 때문에 데이터를 조합하고 찾는 과정은 매우 복잡합니다. 데이터 하나를 출력하기 위해 여러 개의 노드가 서로 정보를 공유하는 과정이 필요합니다.
(2) 데이터 처리 지연
샤드 간 통신이 빈번해지면 오히려 데이터 처리가 지연되는 경우가 있습니다. 시스템 전체적인 안정성은 샤딩을 통해 강화할 수 있으나 샤드 간 불균형이 일어나 저장 데이터 비율이 자주 변화한다면 재배치가 발생할 수 있습니다. 이 과정에서 트래픽까지 증가한다면 샤딩을 최적화 하는 것에 최선을 다해야 합니다.
위와 같은 샤딩의 문제점을 해결하기 위해서는 샤드의 수를 늘리는 스케일업 작업이 대표적입니다. 또한 샤딩이 최적화 되어 있는지 주기적으로 검토하고 적절한 샤드 키의 선택, 데이터 분산의 복잡성, 샤드간 데이터 일관성 유지 등 많은 것들을 고려하여 적용하여야 합니다.
4. 데이터베이스 샤딩의 종류
샤딩은 파티셔닝과 비슷하게 Range, Hash based, Composite (Range + Hash) 등이 존재합니다.
(1) Range sharding
샤드 증설 시 데이터 재분배가 필요없고 가장 마지막 샤드에 키를 넉넉히 설정한 후, 필요 시점에 샤드를 증설합니다. 그러나 Range Sharding은 활성 레코드가 많은 특정 샤드(Hot Spot)에 부하가 몰릴 수 있는 문제점이 있습니다.

(2) Hash based Sharding
샤드 키를 해시 함수를 통해 분배하는 방법입니다. 주로 Modular 연산을 해시 함수로 사용하며 비교적 고르게 분배할 수 있습니다. 하지만 샤드 추가시 레코드의 재분배가 발생하는 과정이 필요합니다. 보통 두배수로 늘려 이동해야 하는 레코드를 최소화 합니다.(두 배로 늘릴 경우 하나의 샤드가 반으로 분할되기만 하면됨.)


(3) Composite Sharding
Range + Hash Sharding을 복합적으로 사용합니다. 실제 LINE 기술블로그 사례에서 crc32(key) % 65535 결과를 샤드 8개로 나누어 분배한 사례가 있습니다.
LINE 기술블로그 참고 : https://engineering.linecorp.com/ko/blog/line-manga-server-side
crc32(key) % 65535;
# 0 ~ 8191 => 샤드1 # 8192 ~ 16383 => 샤드2
# 16384 ~ 24575 => 샤드3 # 24576 ~ 32767 => 샤드4
# 32768 ~ 40959 => 샤드5 # 40960 ~ 49151 => 샤드6
# 49152 ~ 57343 => 샤드7 # 57344 ~ 65535 => 샤드8
위 경우에는 샤드 증감이 조금 더 수월해집니다. Modular의 경우 샤드를 둘로 쪼갤 키 집합이 순차적이지 않으나 이 경우엔 Range를 반으로 분할하면 됩니다. 마찬가지로 합치는 것도 둘을 하나로 합치면 됩니다.
ex) # 0~8191 -> #0 ~ 4095, #4096 ~ 8191
5. 샤딩의 보완
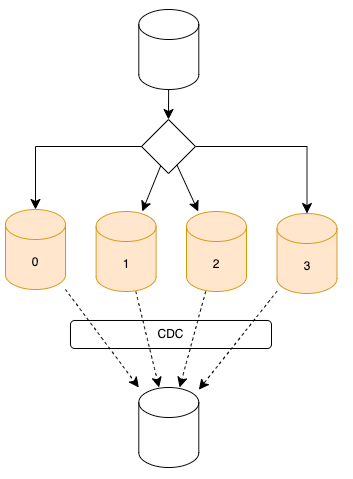
하나의 시스템(데이터베이스)를 여러 개로 분할했으므로 어플리케이션의 복잡도가 증가합니다. 예를 들어 기존 단일 테이블을 대상으로 범위를 조회하던 쿼리나 특히 테이블 간 조인이 빈번하게 발생하는 쿼리는 더 이상 사용이 불가능해 집니다.
이럴 경우 별도 Summary가 되어있는 저장소를 고려할 수 있고, 주기적인 배치로 집계를 해두거나 CDC를 활용하여 실시간 집계 방법도 있습니다. 혹은 MSR(Multi Source Replication)을 활용할 수도 있습니다.
'DBA' 카테고리의 다른 글
| 데이터베이스 해시 조인 (HASH JOIN) (0) | 2024.10.29 |
|---|---|
| 데이터베이스 중첩 루프 조인 (NESTED LOOPS JOIN, NL JOIN) (2) | 2024.10.29 |
| DBMS 별 버전 정보 확인 (1) | 2020.11.30 |
| SQL 작성 표준 (2) | 2020.04.28 |
| 데이터베이스 성능 향상을 위한 규칙/팁 (3) | 2020.04.27 |